【大数据开发】推荐系统之TF |
您所在的位置:网站首页 › TD IDF › 【大数据开发】推荐系统之TF |
【大数据开发】推荐系统之TF
|
■ TF-IDF原理 TF-IDF (term frequency-inverse document frequency)是非常常用的加权方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。 TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。 词频指的是词语在全部内容中出现的频率,频率越高表示词语在文章中的内容重要程度越高。逆文本频率指数能够反映在所有参加对比的文章中,词语出现的频率;词语的这个值越大,它在所有文章中出现的频率越低,词语越重要,也就是物以稀为贵的意思。 ■ TF-IDF计算方法 TF=该词在该文章出现次数/该文章总词数 IDF=log(所有文章数量/包含该词的文章数) TF-IDF=TF和IDF乘积 ■ TF-IDF公式
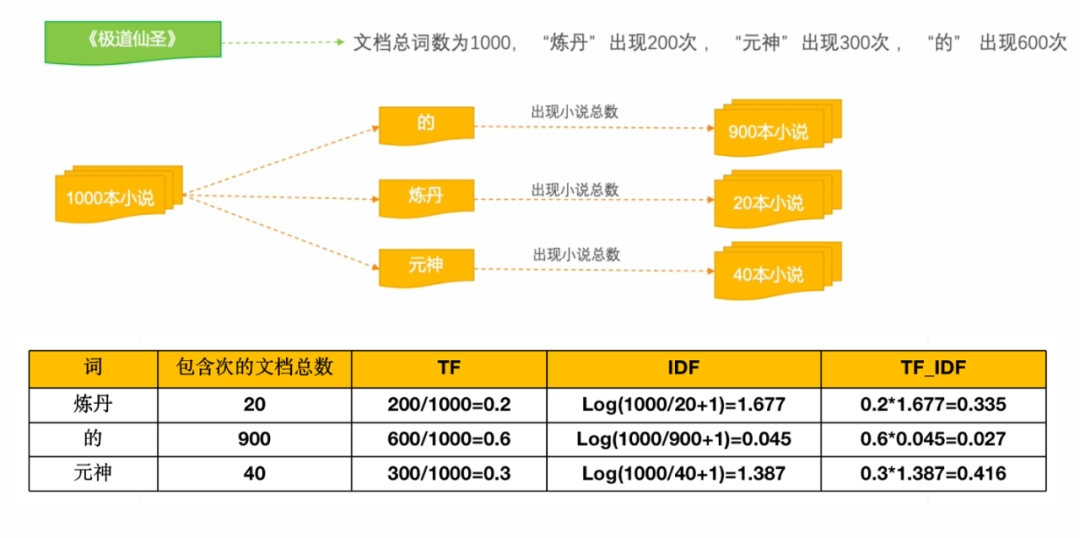
■ TF-IDF举例说明
■ TF-IDF原理总结 TF刻画了词语对某篇文档的重要性,IDF刻画了词语对整个文档集的重要性。 TF创建了计算相似形的初级向量,IDF优化了这种初级向量,形成能够比较准确的计算相似形的结果向量。 TF创建了内容的初级画像,IDF (去除停用词)使内容画像越来越清晰。 ■ 取对数(Log)的意义 缩小数据的绝对数值,方便计算。例如:每个数据项的值都很大,许多这样的值进行计算可能对超过常用数据类型的取值范围,这时取对数,就把数值缩小了,例如TF-IDF计算时,由于在大规模语料库中,很多词的频率是非常大的数字。 取对数之后不会改变数据的性质和相关关系。 |

【本文地址】
今日新闻 |
推荐新闻 |